

SVN 설치/ 사용법
Program/Info Etc 2008. 1. 22. 14:41'Program > Info Etc' 카테고리의 다른 글
| 비쥬얼 스튜디오 필수 유틸 목록 (0) | 2008.02.03 |
|---|---|
| 싱글턴 패턴 (0) | 2008.01.16 |
| MD5 암호화 (0) | 2008.01.16 |
|
'Info'에 해당되는 글 14건SVN 설치/ 사용법Program/Info Etc 2008. 1. 22. 14:41'Program > Info Etc' 카테고리의 다른 글
C# 에서 Win32 함수 쓰기.. C# C++ 자료형 비교Program/C# 2008. 1. 17. 17:03C#에서 Win32 API 사용하기 개요 Win32 API를 불러올 때, 함수의 명칭, 인자, 리턴 값을 가지고 불러오게 되어 있다. 하지만, C#에서 타입들이 모두 객체(Object)의 형식이며, 일반적인 C 의 데이터 형과 상이한 모양을 가진다. 이러한 문제들을 해결할 수 있는 것이 PInvoke 기능이다. PInvoke( Platform Invocation Service)는 관리화 코드에서 비관리화 코드를 호출할 방법을 제공한다. 일반적인 용도는 Win32 API의 호출을 위해 사용한다.
위 예제는 FindWindow라는 user32.dll의 C함수를 사용하는 모습을 보여주고 있다. 실제 FindWindow의 선언은 다음과 같다.
HWND는 윈도우 핸들을 표현하는 32비트 정수 이므로, int형으로 치환되고 LPCSTR 형은 NULL로 끝나는 문자열을 표현한다. 이때 PInvoke는 string을 자동으로 LPCSTR로 치환해 주는 역할을 하게 된다. 이 문서에서는 이처럼 Win32 API 함수의 여러 유형들을 어떻게 C#에서 사용 할 것인지에 대하여 알아보자. WIN32 데이터형의 치환 Win32 API에서 일반적으로 사용하고 있는 데이터형은 모두 C#의 데이터 형으로 치환될 수 있다.
Structure 의 전달 예를 들어 POINT 형의 경우,
이것은 기본적으로 다음과 같이 선언될 수 있다.
일차적으로 할당되는 메모리 레이아웃이 동일하다면, C#에서 바로 받아 들이 수 있다.
사용할 함수 이름 바꾸기 여기서 함수의 이름을 바꿔서 사용하고 싶다면 다음과 같이 변경하면 된다.
레퍼런스형 전달하기 LPPOINT형은 POINT의 포인터 형이므로 ref Point와 같이 사용 할 수 있다. 실제 사용하는 형식은 다음과 같다. C 언어의 포인터의 경우 레퍼런스로 사용하려고 하면, ref 키워드를 사용하는 방법이 있다.
Out형 함수 인자 사용하기 MSDN 같은 곳에서 함수의 선언을 살펴보면 다음과 같은 형식의 함수를 볼 수 있을 것이다. 이러한 형식은 레퍼런스 형으로 결과를 함수의 인자에 보내겠다는 말이다. 이러한 형식은 Win32 API에서 많이 쓰이고 있고, 포인터를 사용하므로, 많은 주의를 기울여야 한다.
여기서 LPRECT는 앞 절에서 설명한 Structure의 전달을 참고하여 치환 될 수 있다. 여기서 lpRect는 RECT의 포인터이며, GetWindowRect 함수 내에서 이 포인터에 직접 값을 쓰게 되어 있다. 즉 이 포인터는 값을 기록하기 위한 인자이지, 값을 전달하기 위한 인자는 아닌 것이다. 이것은 또 다른 C# 레퍼런스 연산자인 out 키워드를 사용하여 쉽게 해결 할 수 있다.
실제 사용하는 모습은 다음과 같다.
참고로 ref 키워드는 입력과 출력 둘 다 사용 할 수 있다. 그러나 ref를 사용하는 변수가 값이 설정되어 있다는 가정을 하고 있으므로, 이전에 반드시 어떠한 값을 입력해야 한다. 실제 사용 예는 다음과 같다.
여기서 잠깐 대중없이 Rect라는 구조체가 나오는데 이는 API에서 RECT형을 C#으로 바꾸어 사용하는 structure이다. 앞의 예제들은 다음과 같은 선언을 하였다고 가정한다.
CALLBACK 함수의 선언 C 언어에서 콜백 함수는 함수 포인터로 존재하게 된다. 이것은 함수 인스턴스의 포인터로, 함수 자체를 전달하게 되는 방식이다. 대표적으로 사용되는 부분은 EnumWindows 함수이다.
이 함수는 현재 열려 있는 모든 윈도우 핸들을 열거하기 위한 함수로 실제 처리하는 부분은 함수 포인터, 즉 콜백함수인 lpEnumFunc에서 처리하게 되어 있다. WNDENUMPROC 타입의 선언은 다음과 같다.
이러한 콜백 함수 역할을 하는 C#의 프리미티브는 delegate이다. CALLBACK은 delegate로 지환된다. 결과적으로 다음과 같이 사용하게 된다.
출처 : 데브피아~~~~ 'Program > C#' 카테고리의 다른 글
임시폴더, 응용프로그램 경로 알기. 윈도우 핸들로 포인터 얻기Program/C | C++ 2008. 1. 16. 23:12GetTempPath(~
GetMoudleFileName(~ CWnd::FromHandle(~ 'Program > C | C++' 카테고리의 다른 글
파일 관련 함수들..Program/C | C++ 2008. 1. 16. 23:11API
PathFileExists(~ CopyFile(~ Delete File(~ MoveFile(~ CreateDirectory(~ CreateFile(~ RemoveFolder(~ Rename(~ RenameDirectory(~ . . . 'Program > C | C++' 카테고리의 다른 글
MD5 암호화Program/Info Etc 2008. 1. 16. 09:53출처 : http://www.faqs.org/rfcs/rfc1321.html
Network Working Group R. Rivest Request for Comments: 1321 MIT Laboratory for Computer Science and RSA Data Security, Inc. April 1992 The MD5 Message-Digest Algorithm Status of this Memo This memo provides information for the Internet community. It does not specify an Internet standard. Distribution of this memo is unlimited. Acknowlegements We would like to thank Don Coppersmith, Burt Kaliski, Ralph Merkle, David Chaum, and Noam Nisan for numerous helpful comments and suggestions. Table of Contents 1. Executive Summary 1 2. Terminology and Notation 2 3. MD5 Algorithm Description 3 4. Summary 6 5. Differences Between MD4 and MD5 6 References 7 APPENDIX A - Reference Implementation 7 Security Considerations 21 Author's Address 21 1. Executive Summary This document describes the MD5 message-digest algorithm. The algorithm takes as input a message of arbitrary length and produces as output a 128-bit "fingerprint" or "message digest" of the input. It is conjectured that it is computationally infeasible to produce two messages having the same message digest, or to produce any message having a given prespecified target message digest. The MD5 algorithm is intended for digital signature applications, where a large file must be "compressed" in a secure manner before being encrypted with a private (secret) key under a public-key cryptosystem such as RSA. The MD5 algorithm is designed to be quite fast on 32-bit machines. In addition, the MD5 algorithm does not require any large substitution tables; the algorithm can be coded quite compactly. The MD5 algorithm is an extension of the MD4 message-digest algorithm 1,2]. MD5 is slightly slower than MD4, but is more "conservative" in design. MD5 was designed because it was felt that MD4 was perhaps being adopted for use more quickly than justified by the existing critical review; because MD4 was designed to be exceptionally fast, it is "at the edge" in terms of risking successful cryptanalytic attack. MD5 backs off a bit, giving up a little in speed for a much greater likelihood of ultimate security. It incorporates some suggestions made by various reviewers, and contains additional optimizations. The MD5 algorithm is being placed in the public domain for review and possible adoption as a standard. For OSI-based applications, MD5's object identifier is md5 OBJECT IDENTIFIER ::= iso(1) member-body(2) US(840) rsadsi(113549) digestAlgorithm(2) 5} In the X.509 type AlgorithmIdentifier [3], the parameters for MD5 should have type NULL. 2. Terminology and Notation In this document a "word" is a 32-bit quantity and a "byte" is an eight-bit quantity. A sequence of bits can be interpreted in a natural manner as a sequence of bytes, where each consecutive group of eight bits is interpreted as a byte with the high-order (most significant) bit of each byte listed first. Similarly, a sequence of bytes can be interpreted as a sequence of 32-bit words, where each consecutive group of four bytes is interpreted as a word with the low-order (least significant) byte given first. Let x_i denote "x sub i". If the subscript is an expression, we surround it in braces, as in x_{i+1}. Similarly, we use ^ for superscripts (exponentiation), so that x^i denotes x to the i-th power. Let the symbol "+" denote addition of words (i.e., modulo-2^32 addition). Let X <<< s denote the 32-bit value obtained by circularly shifting (rotating) X left by s bit positions. Let not(X) denote the bit-wise complement of X, and let X v Y denote the bit-wise OR of X and Y. Let X xor Y denote the bit-wise XOR of X and Y, and let XY denote the bit-wise AND of X and Y. 3. MD5 Algorithm Description We begin by supposing that we have a b-bit message as input, and that we wish to find its message digest. Here b is an arbitrary nonnegative integer; b may be zero, it need not be a multiple of eight, and it may be arbitrarily large. We imagine the bits of the message written down as follows: m_0 m_1 ... m_{b-1} The following five steps are performed to compute the message digest of the message. 3.1 Step 1. Append Padding Bits The message is "padded" (extended) so that its length (in bits) is congruent to 448, modulo 512. That is, the message is extended so that it is just 64 bits shy of being a multiple of 512 bits long. Padding is always performed, even if the length of the message is already congruent to 448, modulo 512. Padding is performed as follows: a single "1" bit is appended to the message, and then "0" bits are appended so that the length in bits of the padded message becomes congruent to 448, modulo 512. In all, at least one bit and at most 512 bits are appended. 3.2 Step 2. Append Length A 64-bit representation of b (the length of the message before the padding bits were added) is appended to the result of the previous step. In the unlikely event that b is greater than 2^64, then only the low-order 64 bits of b are used. (These bits are appended as two 32-bit words and appended low-order word first in accordance with the previous conventions.) At this point the resulting message (after padding with bits and with b) has a length that is an exact multiple of 512 bits. Equivalently, this message has a length that is an exact multiple of 16 (32-bit) words. Let M[0 ... N-1] denote the words of the resulting message, where N is a multiple of 16. 3.3 Step 3. Initialize MD Buffer A four-word buffer (A,B,C,D) is used to compute the message digest. Here each of A, B, C, D is a 32-bit register. These registers are initialized to the following values in hexadecimal, low-order bytes first): word A: 01 23 45 67 word B: 89 ab cd ef word C: fe dc ba 98 word D: 76 54 32 10 3.4 Step 4. Process Message in 16-Word Blocks We first define four auxiliary functions that each take as input three 32-bit words and produce as output one 32-bit word. F(X,Y,Z) = XY v not(X) Z G(X,Y,Z) = XZ v Y not(Z) H(X,Y,Z) = X xor Y xor Z I(X,Y,Z) = Y xor (X v not(Z)) In each bit position F acts as a conditional: if X then Y else Z. The function F could have been defined using + instead of v since XY and not(X)Z will never have 1's in the same bit position.) It is interesting to note that if the bits of X, Y, and Z are independent and unbiased, the each bit of F(X,Y,Z) will be independent and unbiased. The functions G, H, and I are similar to the function F, in that they act in "bitwise parallel" to produce their output from the bits of X, Y, and Z, in such a manner that if the corresponding bits of X, Y, and Z are independent and unbiased, then each bit of G(X,Y,Z), H(X,Y,Z), and I(X,Y,Z) will be independent and unbiased. Note that the function H is the bit-wise "xor" or "parity" function of its inputs. This step uses a 64-element table T[1 ... 64] constructed from the sine function. Let T[i] denote the i-th element of the table, which is equal to the integer part of 4294967296 times abs(sin(i)), where i is in radians. The elements of the table are given in the appendix. Do the following: /* Process each 16-word block. */ For i = 0 to N/16-1 do /* Copy block i into X. */ For j = 0 to 15 do Set X[j] to M[i*16+j]. end /* of loop on j */ /* Save A as AA, B as BB, C as CC, and D as DD. */ AA = A BB = B CC = C DD = D /* Round 1. */ /* Let [abcd k s i] denote the operation a = b + ((a + F(b,c,d) + X[k] + T[i]) <<< s). */ /* Do the following 16 operations. */ [ABCD 0 7 1] [DABC 1 12 2] [CDAB 2 17 3] [BCDA 3 22 4] [ABCD 4 7 5] [DABC 5 12 6] [CDAB 6 17 7] [BCDA 7 22 8] [ABCD 8 7 9] [DABC 9 12 10] [CDAB 10 17 11] [BCDA 11 22 12] [ABCD 12 7 13] [DABC 13 12 14] [CDAB 14 17 15] [BCDA 15 22 16] /* Round 2. */ /* Let [abcd k s i] denote the operation a = b + ((a + G(b,c,d) + X[k] + T[i]) <<< s). */ /* Do the following 16 operations. */ [ABCD 1 5 17] [DABC 6 9 18] [CDAB 11 14 19] [BCDA 0 20 20] [ABCD 5 5 21] [DABC 10 9 22] [CDAB 15 14 23] [BCDA 4 20 24] [ABCD 9 5 25] [DABC 14 9 26] [CDAB 3 14 27] [BCDA 8 20 28] [ABCD 13 5 29] [DABC 2 9 30] [CDAB 7 14 31] [BCDA 12 20 32] /* Round 3. */ /* Let [abcd k s t] denote the operation a = b + ((a + H(b,c,d) + X[k] + T[i]) <<< s). */ /* Do the following 16 operations. */ [ABCD 5 4 33] [DABC 8 11 34] [CDAB 11 16 35] [BCDA 14 23 36] [ABCD 1 4 37] [DABC 4 11 38] [CDAB 7 16 39] [BCDA 10 23 40] [ABCD 13 4 41] [DABC 0 11 42] [CDAB 3 16 43] [BCDA 6 23 44] [ABCD 9 4 45] [DABC 12 11 46] [CDAB 15 16 47] [BCDA 2 23 48] /* Round 4. */ /* Let [abcd k s t] denote the operation a = b + ((a + I(b,c,d) + X[k] + T[i]) <<< s). */ /* Do the following 16 operations. */ [ABCD 0 6 49] [DABC 7 10 50] [CDAB 14 15 51] [BCDA 5 21 52] [ABCD 12 6 53] [DABC 3 10 54] [CDAB 10 15 55] [BCDA 1 21 56] [ABCD 8 6 57] [DABC 15 10 58] [CDAB 6 15 59] [BCDA 13 21 60] [ABCD 4 6 61] [DABC 11 10 62] [CDAB 2 15 63] [BCDA 9 21 64] /* Then perform the following additions. (That is increment each of the four registers by the value it had before this block was started.) */ A = A + AA B = B + BB C = C + CC D = D + DD end /* of loop on i */ 3.5 Step 5. Output The message digest produced as output is A, B, C, D. That is, we begin with the low-order byte of A, and end with the high-order byte of D. This completes the description of MD5. A reference implementation in C is given in the appendix. 4. Summary The MD5 message-digest algorithm is simple to implement, and provides a "fingerprint" or message digest of a message of arbitrary length. It is conjectured that the difficulty of coming up with two messages having the same message digest is on the order of 2^64 operations, and that the difficulty of coming up with any message having a given message digest is on the order of 2^128 operations. The MD5 algorithm has been carefully scrutinized for weaknesses. It is, however, a relatively new algorithm and further security analysis is of course justified, as is the case with any new proposal of this sort. 5. Differences Between MD4 and MD5 The following are the differences between MD4 and MD5: 1. A fourth round has been added. 2. Each step now has a unique additive constant. 3. The function g in round 2 was changed from (XY v XZ v YZ) to (XZ v Y not(Z)) to make g less symmetric. 4. Each step now adds in the result of the previous step. This promotes a faster "avalanche effect". 5. The order in which input words are accessed in rounds 2 and 3 is changed, to make these patterns less like each other. 6. The shift amounts in each round have been approximately optimized, to yield a faster "avalanche effect." The shifts in different rounds are distinct. References [1] Rivest, R., "The MD4 Message Digest Algorithm", RFC 1320, MIT and RSA Data Security, Inc., April 1992. [2] Rivest, R., "The MD4 message digest algorithm", in A.J. Menezes and S.A. Vanstone, editors, Advances in Cryptology - CRYPTO '90 Proceedings, pages 303-311, Springer-Verlag, 1991. [3] CCITT Recommendation X.509 (1988), "The Directory - Authentication Framework." APPENDIX A - Reference Implementation This appendix contains the following files taken from RSAREF: A Cryptographic Toolkit for Privacy-Enhanced Mail: global.h -- global header file md5.h -- header file for MD5 md5c.c -- source code for MD5 For more information on RSAREF, send email to <rsaref@rsa.com>. The appendix also includes the following file: mddriver.c -- test driver for MD2, MD4 and MD5 The driver compiles for MD5 by default but can compile for MD2 or MD4 if the symbol MD is defined on the C compiler command line as 2 or 4. The implementation is portable and should work on many different plaforms. However, it is not difficult to optimize the implementation on particular platforms, an exercise left to the reader. For example, on "little-endian" platforms where the lowest-addressed byte in a 32- bit word is the least significant and there are no alignment restrictions, the call to Decode in MD5Transform can be replaced with a typecast. A.1 global.h /* GLOBAL.H - RSAREF types and constants */ /* PROTOTYPES should be set to one if and only if the compiler supports function argument prototyping. The following makes PROTOTYPES default to 0 if it has not already been defined with C compiler flags. */ #ifndef PROTOTYPES #define PROTOTYPES 0 #endif /* POINTER defines a generic pointer type */ typedef unsigned char *POINTER; /* UINT2 defines a two byte word */ typedef unsigned short int UINT2; /* UINT4 defines a four byte word */ typedef unsigned long int UINT4; /* PROTO_LIST is defined depending on how PROTOTYPES is defined above. If using PROTOTYPES, then PROTO_LIST returns the list, otherwise it returns an empty list. */ #if PROTOTYPES #define PROTO_LIST(list) list #else #define PROTO_LIST(list) () #endif A.2 md5.h /* MD5.H - header file for MD5C.C */ /* Copyright (C) 1991-2, RSA Data Security, Inc. Created 1991. All rights reserved. License to copy and use this software is granted provided that it is identified as the "RSA Data Security, Inc. MD5 Message-Digest Algorithm" in all material mentioning or referencing this software or this function. License is also granted to make and use derivative works provided that such works are identified as "derived from the RSA Data Security, Inc. MD5 Message-Digest Algorithm" in all material mentioning or referencing the derived work. RSA Data Security, Inc. makes no representations concerning either the merchantability of this software or the suitability of this software for any particular purpose. It is provided "as is" without express or implied warranty of any kind. These notices must be retained in any copies of any part of this documentation and/or software. */ /* MD5 context. */ typedef struct { UINT4 state[4]; /* state (ABCD) */ UINT4 count[2]; /* number of bits, modulo 2^64 (lsb first) */ unsigned char buffer[64]; /* input buffer */ } MD5_CTX; void MD5Init PROTO_LIST ((MD5_CTX *)); void MD5Update PROTO_LIST ((MD5_CTX *, unsigned char *, unsigned int)); void MD5Final PROTO_LIST ((unsigned char [16], MD5_CTX *)); A.3 md5c.c /* MD5C.C - RSA Data Security, Inc., MD5 message-digest algorithm */ /* Copyright (C) 1991-2, RSA Data Security, Inc. Created 1991. All rights reserved. License to copy and use this software is granted provided that it is identified as the "RSA Data Security, Inc. MD5 Message-Digest Algorithm" in all material mentioning or referencing this software or this function. License is also granted to make and use derivative works provided that such works are identified as "derived from the RSA Data Security, Inc. MD5 Message-Digest Algorithm" in all material mentioning or referencing the derived work. RSA Data Security, Inc. makes no representations concerning either the merchantability of this software or the suitability of this software for any particular purpose. It is provided "as is" without express or implied warranty of any kind. These notices must be retained in any copies of any part of this documentation and/or software. */ #include "global.h" #include "md5.h" /* Constants for MD5Transform routine. */ #define S11 7 #define S12 12 #define S13 17 #define S14 22 #define S21 5 #define S22 9 #define S23 14 #define S24 20 #define S31 4 #define S32 11 #define S33 16 #define S34 23 #define S41 6 #define S42 10 #define S43 15 #define S44 21 static void MD5Transform PROTO_LIST ((UINT4 [4], unsigned char [64])); static void Encode PROTO_LIST ((unsigned char *, UINT4 *, unsigned int)); static void Decode PROTO_LIST ((UINT4 *, unsigned char *, unsigned int)); static void MD5_memcpy PROTO_LIST ((POINTER, POINTER, unsigned int)); static void MD5_memset PROTO_LIST ((POINTER, int, unsigned int)); static unsigned char PADDING[64] = { 0x80, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 }; /* F, G, H and I are basic MD5 functions. */ #define F(x, y, z) (((x) & (y)) | ((~x) & (z))) #define G(x, y, z) (((x) & (z)) | ((y) & (~z))) #define H(x, y, z) ((x) ^ (y) ^ (z)) #define I(x, y, z) ((y) ^ ((x) | (~z))) /* ROTATE_LEFT rotates x left n bits. */ #define ROTATE_LEFT(x, n) (((x) << (n)) | ((x) >> (32-(n)))) /* FF, GG, HH, and II transformations for rounds 1, 2, 3, and 4. Rotation is separate from addition to prevent recomputation. */ #define FF(a, b, c, d, x, s, ac) { \ (a) += F ((b), (c), (d)) + (x) + (UINT4)(ac); \ (a) = ROTATE_LEFT ((a), (s)); \ (a) += (b); \ } #define GG(a, b, c, d, x, s, ac) { \ (a) += G ((b), (c), (d)) + (x) + (UINT4)(ac); \ (a) = ROTATE_LEFT ((a), (s)); \ (a) += (b); \ } #define HH(a, b, c, d, x, s, ac) { \ (a) += H ((b), (c), (d)) + (x) + (UINT4)(ac); \ (a) = ROTATE_LEFT ((a), (s)); \ (a) += (b); \ } #define II(a, b, c, d, x, s, ac) { \ (a) += I ((b), (c), (d)) + (x) + (UINT4)(ac); \ (a) = ROTATE_LEFT ((a), (s)); \ (a) += (b); \ } /* MD5 initialization. Begins an MD5 operation, writing a new context. */ void MD5Init (context) MD5_CTX *context; /* context */ { context->count[0] = context->count[1] = 0; /* Load magic initialization constants. */ context->state[0] = 0x67452301; context->state[1] = 0xefcdab89; context->state[2] = 0x98badcfe; context->state[3] = 0x10325476; } /* MD5 block update operation. Continues an MD5 message-digest operation, processing another message block, and updating the context. */ void MD5Update (context, input, inputLen) MD5_CTX *context; /* context */ unsigned char *input; /* input block */ unsigned int inputLen; /* length of input block */ { unsigned int i, index, partLen; /* Compute number of bytes mod 64 */ index = (unsigned int)((context->count[0] >> 3) & 0x3F); /* Update number of bits */ if ((context->count[0] += ((UINT4)inputLen << 3)) < ((UINT4)inputLen << 3)) context->count[1]++; context->count[1] += ((UINT4)inputLen >> 29); partLen = 64 - index; /* Transform as many times as possible. */ if (inputLen >= partLen) { MD5_memcpy ((POINTER)&context->buffer[index], (POINTER)input, partLen); MD5Transform (context->state, context->buffer); for (i = partLen; i + 63 < inputLen; i += 64) MD5Transform (context->state, &input[i]); index = 0; } else i = 0; /* Buffer remaining input */ MD5_memcpy ((POINTER)&context->buffer[index], (POINTER)&input[i], inputLen-i); } /* MD5 finalization. Ends an MD5 message-digest operation, writing the the message digest and zeroizing the context. */ void MD5Final (digest, context) unsigned char digest[16]; /* message digest */ MD5_CTX *context; /* context */ { unsigned char bits[8]; unsigned int index, padLen; /* Save number of bits */ Encode (bits, context->count, 8); /* Pad out to 56 mod 64. */ index = (unsigned int)((context->count[0] >> 3) & 0x3f); padLen = (index < 56) ? (56 - index) : (120 - index); MD5Update (context, PADDING, padLen); /* Append length (before padding) */ MD5Update (context, bits, 8); /* Store state in digest */ Encode (digest, context->state, 16); /* Zeroize sensitive information. */ MD5_memset ((POINTER)context, 0, sizeof (*context)); } /* MD5 basic transformation. Transforms state based on block. */ static void MD5Transform (state, block) UINT4 state[4]; unsigned char block[64]; { UINT4 a = state[0], b = state[1], c = state[2], d = state[3], x[16]; Decode (x, block, 64); /* Round 1 */ FF (a, b, c, d, x[ 0], S11, 0xd76aa478); /* 1 */ FF (d, a, b, c, x[ 1], S12, 0xe8c7b756); /* 2 */ FF (c, d, a, b, x[ 2], S13, 0x242070db); /* 3 */ FF (b, c, d, a, x[ 3], S14, 0xc1bdceee); /* 4 */ FF (a, b, c, d, x[ 4], S11, 0xf57c0faf); /* 5 */ FF (d, a, b, c, x[ 5], S12, 0x4787c62a); /* 6 */ FF (c, d, a, b, x[ 6], S13, 0xa8304613); /* 7 */ FF (b, c, d, a, x[ 7], S14, 0xfd469501); /* 8 */ FF (a, b, c, d, x[ 8], S11, 0x698098d8); /* 9 */ FF (d, a, b, c, x[ 9], S12, 0x8b44f7af); /* 10 */ FF (c, d, a, b, x[10], S13, 0xffff5bb1); /* 11 */ FF (b, c, d, a, x[11], S14, 0x895cd7be); /* 12 */ FF (a, b, c, d, x[12], S11, 0x6b901122); /* 13 */ FF (d, a, b, c, x[13], S12, 0xfd987193); /* 14 */ FF (c, d, a, b, x[14], S13, 0xa679438e); /* 15 */ FF (b, c, d, a, x[15], S14, 0x49b40821); /* 16 */ /* Round 2 */ GG (a, b, c, d, x[ 1], S21, 0xf61e2562); /* 17 */ GG (d, a, b, c, x[ 6], S22, 0xc040b340); /* 18 */ GG (c, d, a, b, x[11], S23, 0x265e5a51); /* 19 */ GG (b, c, d, a, x[ 0], S24, 0xe9b6c7aa); /* 20 */ GG (a, b, c, d, x[ 5], S21, 0xd62f105d); /* 21 */ GG (d, a, b, c, x[10], S22, 0x2441453); /* 22 */ GG (c, d, a, b, x[15], S23, 0xd8a1e681); /* 23 */ GG (b, c, d, a, x[ 4], S24, 0xe7d3fbc8); /* 24 */ GG (a, b, c, d, x[ 9], S21, 0x21e1cde6); /* 25 */ GG (d, a, b, c, x[14], S22, 0xc33707d6); /* 26 */ GG (c, d, a, b, x[ 3], S23, 0xf4d50d87); /* 27 */ GG (b, c, d, a, x[ 8], S24, 0x455a14ed); /* 28 */ GG (a, b, c, d, x[13], S21, 0xa9e3e905); /* 29 */ GG (d, a, b, c, x[ 2], S22, 0xfcefa3f8); /* 30 */ GG (c, d, a, b, x[ 7], S23, 0x676f02d9); /* 31 */ GG (b, c, d, a, x[12], S24, 0x8d2a4c8a); /* 32 */ /* Round 3 */ HH (a, b, c, d, x[ 5], S31, 0xfffa3942); /* 33 */ HH (d, a, b, c, x[ 8], S32, 0x8771f681); /* 34 */ HH (c, d, a, b, x[11], S33, 0x6d9d6122); /* 35 */ HH (b, c, d, a, x[14], S34, 0xfde5380c); /* 36 */ HH (a, b, c, d, x[ 1], S31, 0xa4beea44); /* 37 */ HH (d, a, b, c, x[ 4], S32, 0x4bdecfa9); /* 38 */ HH (c, d, a, b, x[ 7], S33, 0xf6bb4b60); /* 39 */ HH (b, c, d, a, x[10], S34, 0xbebfbc70); /* 40 */ HH (a, b, c, d, x[13], S31, 0x289b7ec6); /* 41 */ HH (d, a, b, c, x[ 0], S32, 0xeaa127fa); /* 42 */ HH (c, d, a, b, x[ 3], S33, 0xd4ef3085); /* 43 */ HH (b, c, d, a, x[ 6], S34, 0x4881d05); /* 44 */ HH (a, b, c, d, x[ 9], S31, 0xd9d4d039); /* 45 */ HH (d, a, b, c, x[12], S32, 0xe6db99e5); /* 46 */ HH (c, d, a, b, x[15], S33, 0x1fa27cf8); /* 47 */ HH (b, c, d, a, x[ 2], S34, 0xc4ac5665); /* 48 */ /* Round 4 */ II (a, b, c, d, x[ 0], S41, 0xf4292244); /* 49 */ II (d, a, b, c, x[ 7], S42, 0x432aff97); /* 50 */ II (c, d, a, b, x[14], S43, 0xab9423a7); /* 51 */ II (b, c, d, a, x[ 5], S44, 0xfc93a039); /* 52 */ II (a, b, c, d, x[12], S41, 0x655b59c3); /* 53 */ II (d, a, b, c, x[ 3], S42, 0x8f0ccc92); /* 54 */ II (c, d, a, b, x[10], S43, 0xffeff47d); /* 55 */ II (b, c, d, a, x[ 1], S44, 0x85845dd1); /* 56 */ II (a, b, c, d, x[ 8], S41, 0x6fa87e4f); /* 57 */ II (d, a, b, c, x[15], S42, 0xfe2ce6e0); /* 58 */ II (c, d, a, b, x[ 6], S43, 0xa3014314); /* 59 */ II (b, c, d, a, x[13], S44, 0x4e0811a1); /* 60 */ II (a, b, c, d, x[ 4], S41, 0xf7537e82); /* 61 */ II (d, a, b, c, x[11], S42, 0xbd3af235); /* 62 */ II (c, d, a, b, x[ 2], S43, 0x2ad7d2bb); /* 63 */ II (b, c, d, a, x[ 9], S44, 0xeb86d391); /* 64 */ state[0] += a; state[1] += b; state[2] += c; state[3] += d; /* Zeroize sensitive information. */ MD5_memset ((POINTER)x, 0, sizeof (x)); } /* Encodes input (UINT4) into output (unsigned char). Assumes len is a multiple of 4. */ static void Encode (output, input, len) unsigned char *output; UINT4 *input; unsigned int len; { unsigned int i, j; for (i = 0, j = 0; j < len; i++, j += 4) { output[j] = (unsigned char)(input[i] & 0xff); output[j+1] = (unsigned char)((input[i] >> 8) & 0xff); output[j+2] = (unsigned char)((input[i] >> 16) & 0xff); output[j+3] = (unsigned char)((input[i] >> 24) & 0xff); } } /* Decodes input (unsigned char) into output (UINT4). Assumes len is a multiple of 4. */ static void Decode (output, input, len) UINT4 *output; unsigned char *input; unsigned int len; { unsigned int i, j; for (i = 0, j = 0; j < len; i++, j += 4) output[i] = ((UINT4)input[j]) | (((UINT4)input[j+1]) << 8) | (((UINT4)input[j+2]) << 16) | (((UINT4)input[j+3]) << 24); } /* Note: Replace "for loop" with standard memcpy if possible. */ static void MD5_memcpy (output, input, len) POINTER output; POINTER input; unsigned int len; { unsigned int i; for (i = 0; i < len; i++) output[i] = input[i]; } /* Note: Replace "for loop" with standard memset if possible. */ static void MD5_memset (output, value, len) POINTER output; int value; unsigned int len; { unsigned int i; for (i = 0; i < len; i++) ((char *)output)[i] = (char)value; } A.4 mddriver.c /* MDDRIVER.C - test driver for MD2, MD4 and MD5 */ /* Copyright (C) 1990-2, RSA Data Security, Inc. Created 1990. All rights reserved. RSA Data Security, Inc. makes no representations concerning either the merchantability of this software or the suitability of this software for any particular purpose. It is provided "as is" without express or implied warranty of any kind. These notices must be retained in any copies of any part of this documentation and/or software. */ /* The following makes MD default to MD5 if it has not already been defined with C compiler flags. */ #ifndef MD #define MD MD5 #endif #include <stdio.h> #include <time.h> #include <string.h> #include "global.h" #if MD == 2 #include "md2.h" #endif #if MD == 4 #include "md4.h" #endif #if MD == 5 #include "md5.h" #endif /* Length of test block, number of test blocks. */ #define TEST_BLOCK_LEN 1000 #define TEST_BLOCK_COUNT 1000 static void MDString PROTO_LIST ((char *)); static void MDTimeTrial PROTO_LIST ((void)); static void MDTestSuite PROTO_LIST ((void)); static void MDFile PROTO_LIST ((char *)); static void MDFilter PROTO_LIST ((void)); static void MDPrint PROTO_LIST ((unsigned char [16])); #if MD == 2 #define MD_CTX MD2_CTX #define MDInit MD2Init #define MDUpdate MD2Update #define MDFinal MD2Final #endif #if MD == 4 #define MD_CTX MD4_CTX #define MDInit MD4Init #define MDUpdate MD4Update #define MDFinal MD4Final #endif #if MD == 5 #define MD_CTX MD5_CTX #define MDInit MD5Init #define MDUpdate MD5Update #define MDFinal MD5Final #endif /* Main driver. Arguments (may be any combination): -sstring - digests string -t - runs time trial -x - runs test script filename - digests file (none) - digests standard input */ int main (argc, argv) int argc; char *argv[]; { int i; if (argc > 1) for (i = 1; i < argc; i++) if (argv[i][0] == '-' && argv[i][1] == 's') MDString (argv[i] + 2); else if (strcmp (argv[i], "-t") == 0) MDTimeTrial (); else if (strcmp (argv[i], "-x") == 0) MDTestSuite (); else MDFile (argv[i]); else MDFilter (); return (0); } /* Digests a string and prints the result. */ static void MDString (string) char *string; { MD_CTX context; unsigned char digest[16]; unsigned int len = strlen (string); MDInit (&context); MDUpdate (&context, string, len); MDFinal (digest, &context); printf ("MD%d (\"%s\") = ", MD, string); MDPrint (digest); printf ("\n"); } /* Measures the time to digest TEST_BLOCK_COUNT TEST_BLOCK_LEN-byte blocks. */ static void MDTimeTrial () { MD_CTX context; time_t endTime, startTime; unsigned char block[TEST_BLOCK_LEN], digest[16]; unsigned int i; printf ("MD%d time trial. Digesting %d %d-byte blocks ...", MD, TEST_BLOCK_LEN, TEST_BLOCK_COUNT); /* Initialize block */ for (i = 0; i < TEST_BLOCK_LEN; i++) block[i] = (unsigned char)(i & 0xff); /* Start timer */ time (&startTime); /* Digest blocks */ MDInit (&context); for (i = 0; i < TEST_BLOCK_COUNT; i++) MDUpdate (&context, block, TEST_BLOCK_LEN); MDFinal (digest, &context); /* Stop timer */ time (&endTime); printf (" done\n"); printf ("Digest = "); MDPrint (digest); printf ("\nTime = %ld seconds\n", (long)(endTime-startTime)); printf ("Speed = %ld bytes/second\n", (long)TEST_BLOCK_LEN * (long)TEST_BLOCK_COUNT/(endTime-startTime)); } /* Digests a reference suite of strings and prints the results. */ static void MDTestSuite () { printf ("MD%d test suite:\n", MD); MDString (""); MDString ("a"); MDString ("abc"); MDString ("message digest"); MDString ("abcdefghijklmnopqrstuvwxyz"); MDString ("ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789"); MDString ("1234567890123456789012345678901234567890\ 1234567890123456789012345678901234567890"); } /* Digests a file and prints the result. */ static void MDFile (filename) char *filename; { FILE *file; MD_CTX context; int len; unsigned char buffer[1024], digest[16]; if ((file = fopen (filename, "rb")) == NULL) printf ("%s can't be opened\n", filename); else { MDInit (&context); while (len = fread (buffer, 1, 1024, file)) MDUpdate (&context, buffer, len); MDFinal (digest, &context); fclose (file); printf ("MD%d (%s) = ", MD, filename); MDPrint (digest); printf ("\n"); } } /* Digests the standard input and prints the result. */ static void MDFilter () { MD_CTX context; int len; unsigned char buffer[16], digest[16]; MDInit (&context); while (len = fread (buffer, 1, 16, stdin)) MDUpdate (&context, buffer, len); MDFinal (digest, &context); MDPrint (digest); printf ("\n"); } /* Prints a message digest in hexadecimal. */ static void MDPrint (digest) unsigned char digest[16]; { unsigned int i; for (i = 0; i < 16; i++) printf ("%02x", digest[i]); } A.5 Test suite The MD5 test suite (driver option "-x") should print the following results: MD5 test suite: MD5 ("") = d41d8cd98f00b204e9800998ecf8427e MD5 ("a") = 0cc175b9c0f1b6a831c399e269772661 MD5 ("abc") = 900150983cd24fb0d6963f7d28e17f72 MD5 ("message digest") = f96b697d7cb7938d525a2f31aaf161d0 MD5 ("abcdefghijklmnopqrstuvwxyz") = c3fcd3d76192e4007dfb496cca67e13b MD5 ("ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789") = d174ab98d277d9f5a5611c2c9f419d9f MD5 ("123456789012345678901234567890123456789012345678901234567890123456 78901234567890") = 57edf4a22be3c955ac49da2e2107b67a Security Considerations The level of security discussed in this memo is considered to be sufficient for implementing very high security hybrid digital- signature schemes based on MD5 and a public-key cryptosystem. Author's Address Ronald L. Rivest Massachusetts Institute of Technology Laboratory for Computer Science NE43-324 545 Technology Square Cambridge, MA 02139-1986 Phone: (617) 253-5880 EMail: rivest@theory.lcs.mit.edu 'Program > Info Etc' 카테고리의 다른 글
XML 간단한 설명Program/Info Etc 2008. 1. 16. 09:52XML 정리
XML (eXtensible Markup Language) 정의 ~.xml eXtensible : 확장 가능한 Markup : 마크업 Language : 언어(규칙) 쉽게 표현하면 새로운 태그를 만들 수 있는 규칙 정도의 뜻이다.
XML은 메타 언어(Meta Language) 언어를 표현하는 언어라는 뜻이다. 즉, 태그를 이용하여 문서의 의미를 표현하는 언어라는 뜻이다. 예를 들어 <가수>원더걸스</가수> 에서 원더걸스는 가수라는 추가 정보가 있는 것이다.
XML의 역사 SGML 과 HTML 의 장점을 결합한 것이 XML 이다.
XML 공부하려면 최소한 에디터와 브라우저만 있으면 된다. 1. XML 을 공부하려면 유니 코드를 지원하는 에디터 (메모장, 울트라에디터, 에디트플러스 등) 2. XML 브라우저 (인터넷 익스플로러, 파이어 폭스 등)
XML 문서는 Well-Formed Document와 Valid Document로 나뉜다. 1. Well-Formed Document : 한 마디로 여는 태그와 닫는 태그만 맞으면 된다. 2. Valid Document DTD나 XML 스키마로 XML 문서의 규칙을 지정하는 데 이 규칙에 맞으면 된다.
----------------------------------------------------------
DTD : Document Type Definition ~.dtd XML 문서의 규칙을 지정.
DTD 의 서브셋 텍스트 선언, 엘리먼트 선언, 속성 선언, 엔티티 선언, 노테이션 선언, 프로세싱 지시자 선언, 파라미터 엔티티 참조, 주석, 공백, 컨디셔날 섹션
텍스트 선언 <?xml version="1.0" encoding="UTF-8" ?>
주석 <!-- 주석 --> 엘리먼트 = 태그 1. 여는_태그 <가수> 2. 내용 원더걸스 3. 닫는_태그 </가수> 엘리먼트 내용에 나올 수 있는 것 1. #PCDATA 2. 자식_엘리먼트 3. EMPTY 4. MIXED 5. ANY 자식 엘리먼트 리스트 표현 방법 1. , : <!ELEMENT 연예인 (전화번호, 주소)> ; 전화번호 다음에 주소가 나온다. 2. | : <!ELEMENT 분류 (가수 | 배우)> ; 가수 / 배우 중에 하나가 나온다. 3. ? : 생략하거나 한번만 나온다. 4. + : 한번 이상 5. * : 생략하거나 여러 번 속성의 디폴트 선언 1. #IMPLIED : 생략 가능 2. #REQUIRED : 필수 3. #FIXED : 고정값 4. "임의의_내용" 엔티티 분류 1. 물리적인 저장 단위 분류 : 내부, 외부 2. 사용되는 곳 : 일반, 파라미터 3. 문자인지 여부 : 파스드, 언파스드 빌트인 엔티티 5개 ( < , > , & , " , ' ) 노테이션 == MIME 타입 ---------------------------------------------------------- XML 스키마 : XML Schema ~.xsd DTD 보다 정확한 자료 구조 표현 가능. 외부 스키마 참조 include, import, redifine, anotation 엘리먼트와 속성 선언 element, attribute, simpleType, complexType, group, attributeGroup, notation, anotation ---------------------------------------------------------- XPath (XML Path Language) XML문서에서 태그와 속성에 접근하기 위한 경로를 지정하는 언어. 운영체제의 폴더(디렉토리)에 비유된다. 경로 구분 : 절대 경로, 상대 경로 ---------------------------------------------------------- XSL ( eXtensible Stylesheet Language ) ~.xsl 확장 가능한 스타일 시트 언어 XML 문서를 다양한 형태로 변환할 때 사용한다. XSL 구성 파트 1. XSLT (XSL Transfomation) 2. XPath (XML Path Language) 3. XSL-FO (XSL Fomatting Object) 'Program > Info Etc' 카테고리의 다른 글
USB 자동인식 방지Program/Info Etc 2008. 1. 16. 09:52Usb 자동실행방지
시작-제어판-관리도구-서비스-shell hardware detection- 중지 'Program > Info Etc' 카테고리의 다른 글
SilverLiteProgram/SilverLite | WPF 2008. 1. 16. 09:50음... 크로스 플랫폼, 브라우져 기반의 미디어 플러그인..???
MS : http://www.microsoft.com/silverlight/default_ns.aspx 블로그 : http://cafe.naver.com/mssilverlight.cafe?iframe_url=/ArticleRead.nhn%3Farticleid=716 'Program > SilverLite | WPF' 카테고리의 다른 글
RIA ?Program/SilverLite | WPF 2008. 1. 16. 09:49
RIA란 데스크톱 응용 프로그램의 특징과 기능을 가지는 웹 응용 프로그램
웹 2.0이 인터넷 기술의 새로운 이슈로 등장하고 있다. 웹 2.0과 관련된 여러 기술들 중 RIA는 웹 2.0을 완성하기 위한 사용자와의 접점으로서 많은 주목을 받고 있다. 백문이 불여일견! 우선 RIA로 구현된 사이트를 간단히 살펴보도록 하자. RIA가 적용된 첫 번째 사례는 2002년 TravelClick(http://www.travelclick.net)에 의해 제작된 BroadMoor 호텔(http://www.broadmoor.com)의 OneScreen이라는 예약 시스템이다.
 [브로드무어 호텔의 OneScreen 예약 시스템] 플래시와 콜드퓨전(CFML)로 만들어진 이 시스템은 기존의 5단계 페이지를 거쳐서 진행되었던 예약 업무를 플래시의 화려한 그래픽 사용자 인터페이스를 이용하여 한 페이지로 구현한 것이었다. 이것은 그 당시까지의 여러 페이지를 거쳐 시스템을 구현하던 웹 사용자 인터페이스의 새로운 전환을 가져오게 한 사건이었다. 국내 사례를 한번 살펴보자. Adobe의 플래시(Flash)를 이용하여 구현된 CGV 영화관(http://www.cgv.co.kr)의 예매 서비스로 페이지의 전환 없이 한 페이지에서 영화 정보 확인 및 예매를 할 수 있다.
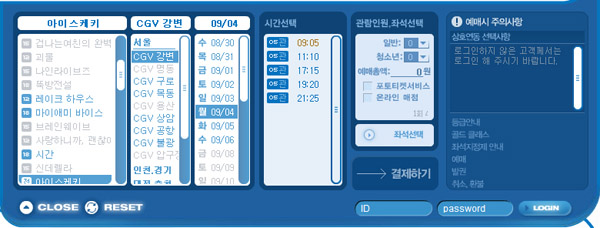 [CGV 극장 영화 예매 시스템] 사용자 인터페이스의 향상과 더불어 사용의 편리성까지 제공할 수 있는 것이 바로 RIA의 가장 강력한 힘인 것이다. RIA를 구현하려면 RIA를 구현하기 위해 다양한 웹 브라우저에서 동작하면서 개발자의 편의를 제공하려는 시도는 여러 업체들에 의해 지금도 계속 중이다. RIA를 구현할 수 있는 기술들을 살펴보면 다음과 같다. l AJAX/DHTML: 자바 스크립트와 XML을 이용한 비동기 호출을 사용하는 방식으로 웹 2.0에서 많은 주목을 받고 있는 기술의 조합이다. 현재 많은 업체에 의해 AJAX를 쉽게 개발할 수 있도록 툴 킷들이 공개되고 있다. l 플래시(Flash): Adobe(이전 Macromedia)의 대표적인 벡터 방식의 그래픽 환경으로 현재 대부분의 브라우저에서 동작한다. 화려한 사용자 인터페이스를 구현하고, 액션스크립트(ActionScript)를 이용하여 비즈니스 로직을 구성할 수 있다. l 플렉스(Flex): Adobe가 소개한 엔터프라이즈 개발을 위한 플랫폼으로 플래시의 SWF로 그 결과물을 출력하나 플래시와는 완전히 다른 새로운 기술이다. l 오픈라즐로(OpenLaszlo): Laszlo System에 의해 시작된 오픈소스 플랫폼으로 RIA 구현을 위해 사용할 수 있으며, LZX라는 새로운 인터페이스 언어를 사용한다. 그 결과물은 플래시 플레이어에서 동작하는 SWF 파일로 출력된다. l WPF: Microsoft에서 새롭게 소개하는 차세대 벡터 방식의 그래픽 환경으로WPF/E를 활용하여 RIA를 구현할 수 있으며, XAML과 Jscript의 기반한 프로그래밍 모델을 가진다. l XUL: XML 기반의 사용자 인터페이스 마크업 언어(User Interface Markup Language)로 모질라(Mozilla) 기반의 웹 브라우저에서 HTML/XHTML을 대신하여 사용할 수 있다. l 액티브X(ActiveX): 윈도우 응용 프로그램을 웹 페이지상에 실행할 수 있는 기술로 마이크로소프트에 의해 소개되었다. 인터넷 익스플로러(IE)에만 동작하는 단점을 가지고 있다. 또한 다른 방식의 RIA 구현과는 다르게 일반적으로 클라이언트에 설치되어 실행하기 위해서는 공인 인증서를 발급(유료)받아야 하는 번거로움이 있다. 물론 브라우저 설정에 따라 이런 과정 없이 설치 및 실행할 수 있으나 클라이언트의 자원을 제어할 수 있는 보안의 취약성이 큰 문제를 발생하기도 한다. l 스마트클라이언트(SmartClient): Microsoft의 닷넷(.NET) 기반의 윈도우 프로그램을 웹 상에서 실행할 수 있는 기술이다. 보안설정과 클라이언트에 닷넷 프레임워크의 설치가 필수이다. l 자바 애플릿(Java applet): 자바 응용 프로그램을 웹 페이지 상에서 실행할 수 있는 기술로 오래 전부터 사용되었다. 다양한 클라이언트의 제어를 할 수 있는 장점에도 불구하고, 느린 속도와 대체 가능한 기술들에 의해 그 사용이 점점 줄어들고 있는 상황이다. l 자바 응용프로그램(Java application): 자바 웹 스타트(Java Web Start)는 자바 응용 프로그램 자체를 웹을 통해 클라이언트에서 실행할 수 있도록 허용한다. 웹을 통해 자바 응용 프로그램을 실행하는 방식으로 RIA를 구현할 수 있다. 이들 중 현재 주류를 이루는 RIA 기술로는 HTML 기반의 RIA 구현에 주로 사용하고 있는 AJAX/DHTML과 화려한 사용자 인터페이스를 구현할 수 있는 플래시가 있다. 새로운 RIA 시장을 선도하기 위해 경쟁적으로 펼치고 있는 새로운 개발 툴의 출시는 정말 흥미진진하게 보인다. 어떤 RIA 기술이 일반 사용자들에게 매력을 줄 것인지, 어떤 개발 툴이 가장 많이 선택 받을지 관심을 가지고 지켜보도록 하자. RIA(Rich Internet Application)란? Rich Internet Application(RIA)이란 전통적인 데스크톱 응용 프로그램의 특징과 기능을 가지는 웹 응용 프로그램이다. 웹 응용 프로그램의 많은 장점에도 불구하고 웹 초창기부터 서버/클라이언트 환경의 윈도우 프로그램에 비해 사용자 인터페이스가 부족하다고 지적되어왔다. 이런 단점을 극복하기 위해 Macromedia(현재 Adobe)는 2002년 리치 인터넷 애플리케이션(RIA)을 처음으로 소개하였다. RIA를 한 마디로 표현한다면 ‘한 페이지로 구현된 웹 응용 프로그램’이라 할 수 있다. 실제 많은 비즈니스 로직이 존재하지만 사용자는 한 페이지를 이용하여 모든 기능을 이용하게 된다. 일반적인 웹 페이지의 페이지 이동과 새로 고침의 깜박임 없이 모든 내용의 확인과 기능을 이용할 수 있는 RIA. 매력적이지 않은가? 왜 RIA인가? 그러면 RIA를 왜 사용하는 것일까? 그 첫 번째로 우리는 웹 응용 프로그램이 가지는 한계점에 대해서 먼저 이해해야 한다. 전통적인 웹 응용 프로그램의 모델은 서버를 중심으로 모든 처리가 수행되고, 사용자의 웹 브라우저를 통해 그 결과를 출력하는 구조로 이루어진다. 우리는 이를 씬 클라이언트(thin client)라 부른다. 즉 클라이언트는 단순히 결과의 디스플레이에만 사용하는 것이다. 그렇기 때문에 서버에서 많은 작업 프로세스가 있는 경우 사용자는 결과가 처리될 때 무작정 기다려야만 하고, 서버의 처리시간이 길어지는 경우 서버와의 통신이 끊어져 더 이상 프로그램을 이용할 수 없는 상황이 발생할 수 있다. 이런 단점을 보안하고, 사용자 인터페이스를 향상하기 위한 시도가 바로 RIA인 것이다. 그렇다면 RIA를 사용하여 얻을 수 있는 장점이 과연 무엇일까? 대표적으로 리치(rich)한 클라이언트 사용자 인터페이스 제공이 있다. RIA 방식으로 구현하면 사용자에게 HTML 위젯(widget)을 사용하는 효과 이상의 보다 그래픽적인 사용자 인터페이스를 공급할 수 있다. 예를 들어, 웹 페이지에서 드래그 & 드롭(drag & drop)이 가능하고, 슬라이드 바를 이용하여 데이터 변경이 가능하게 된다. 또한 클라이언트에 비즈니스 로직 부분을 구현하여 복잡한 계산을 서버가 아닌 클라이언트에서 수행할 수 있다. 그렇기 때문에 일반적으로 보다 향상된 서버의 응답을 구현.할 수 있는 것이다. 이처럼 RIA를 사용하면 사용자 인터페이스의 향상뿐만 아니라 성능 향상의 장점을 가질 수 있다. 즉 RIA에서는 서버와 클라이언트 사이의 부하의 분산이 가능하게 되어 서버의 성능 향상에 도움을 주는 것이다. 또한 비동기 통신(asynchronous communication)을 이용하여 사용자에게 보다 빠른 응답속도를 보이는 것처럼 구현할 수 있다. 사용자가 클릭 하였을 때 그 결과를 미리 비동기 통신으로 저장한 뒤 바로 보여줄 수 있으므로 사용자가 느끼는 체감 속도는 상당히 빨라지고, 서버의 응답 이전에 다른 작업을 수행할 수 있다. 이는 구글 맵(Google Maps)에서 쉽게 확인할 수 있는 방식으로 사용자가 지도를 드래그하면 바로 처리가 되는 것을 확인할 수 있다.
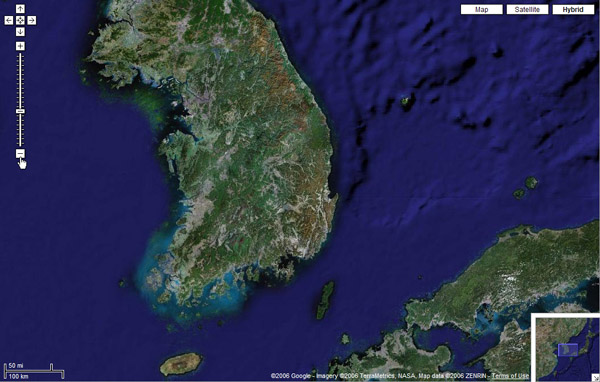 [구글 맵 서비스 (http://maps.google.com)] 마지막으로 네트워크 효율성이 있다. 전통적인 웹 응용 프로그램의 방식은 새로운 결과를 표현하기 위해 전체 페이지의 정보를 전달하고 그 결과를 클라이언트에 다시 보여준다. 하지만 RIA 방식을 이용하면 해당 페이지에서 실제 필요한 일부분의 데이터만 서버로 전달하고, 그 결과를 클라이언트 페이지의 일부 영역에 반영할 수 있기 때문에 네트워크 자원의 사용량도 감소하는 것이다. 더불어 RIA 방식은 초기 프로그램 구동에 시간이 소요된다는 단점이 있지만, 반면에 프로그램 설치가 필요 없다는 장점을 갖고 있다. 그렇기 때문에 사용자들은 어디에서나 쉽게 사용할 수 있고, 프로그램의 버전이 올라가더라도 쉽게 배포할 수 있는 것이다. 이처럼 RIA는 사용자 인터페이스 개선 및 성능 향상이라는 두 마리의 토끼를 잡을 수 있는 현재 진행형의 기술이다. 물론 개발의 난이도가 높아지는 문제가 있지만 사용자들은 이런 개발자들의 고충은 모른다. 자신들이 사용하기 쉽고, 매력적인 프로그램을 선택할 것은 뻔한 이야기라는 것이다. ------------------------------------------------------------------------------------------------------- RIA의 역사 RIA는 2002년 Macromedia에 의해 소개되었지만 개념적으로 유사한 내용들은 이전에도 있었다. 1998년 Microsoft는 Remote Scripting을 소개하였고, 2000년 Forrester Research는 X Internet을 소개하였다. 더불어 리치 클라이언트, 리치 웹 클라이언트 또한 RIA와 유사한 기술적인 분류로 이야기할 수 있다. 그러던 중 2002년에야 비로서 RIA의 실제 적용사례가 소개된다. 앞서 이야기한 플래시와 콜드퓨전(CFML)을 이용한 TravelClick의 Broadmoor 호텔의 OneScreen이라는 예약 시스템이었다. 2004년에는 Macromedia는 플렉스를 엔터프라이즈 개발자를 위한 새로운 플랫폼으로 소개하였다. 기존 플래시가 가졌던 단점을 해결하고 새로운 RIA 개발 환경을 위해 새로운 서버 제품으로 출시하였다. 현재 2.0 버전까지 출시되었으며, 국내외 여러 적용 사례들이 있다. 이러던 중 RIA는 2005년 구글에 의해 사용자들에게 강렬한 인상을 남기게 된다. 바로 구글 맵(http://maps.google.com/) 서비스를 통해 웹 지도에서 드래그, 줌 인/줌 아웃이 구현하였고, 부드러운 화면 전환 및 스크롤을 제공하였다. 이는 마치 윈도우 프로그램을 사용하고 있다는 착각을 가지게 한 아주 충격적인 사건이었다. 이후 웹 2.0에 대한 소개와 실제 구현 사례들을 통해 RIA는 웹 비즈니스의 중요한 요소로 성장하였다. ‘사용자의 눈을 만족시키지 못하는 서비스는 성공하기 힘들다’는 이야기처럼 지금도 사용자들에게 새로운 모습을 보여주기 위하여 여러 웹 사이트들이 RIA를 채택하고 발전을 위한 노력을 계속하고 있는 것이다. ------------------------------------------------------------------------------------------------------- 도스 환경에서 윈도우 프로그램을 처음 사용하였을 때의 GUI 변화에 대한 충격을 기억하는가? 내년에는 윈도우 XP에서 윈도우 Vista로의 새로운 GUI 환경 변화가 우리를 기다리고 있다. 또 얼마나 많은 충격과 변화가 일어날지 아직까지는 느낄 수 없을 것이다. 하지만 분명 변화는 이미 시작되었다는 것이다. 사용자에게 보다 멋진 GUI 환경을 제공하려는 시도는 운영체제, 웹의 구분 없이 계속 될 것이다. 이와 함께 사용자 경험에 아주 밀접한 관계가 있는 RIA는 향후 웹 비즈니스 구현에 가장 중요한 기술로 거듭 자리매김을 할 것이다. 지금의 RIA는 과도기의 모습이다. AJAX와 같은 기술은 잠시 스쳐 지나가는 하나의 흐름일 뿐이다. 앞으로 웹 환경은 벡터 그래픽 환경이 기본이 되고, 3D를 이용한 실제 체험이 가능한 모습으로 변화할 것으로 필자는 확신한다. 쇼핑몰을 이용하면서 자기의 3D 캐릭터에 직접 옷을 입혀본 뒤 제품 구매를 선택하고, 다양한 각도에서 실제 물건 보듯이 살펴볼 수 있는 서비스가 바로 눈앞에 있는 것이다. 여러분들은 RIA와 웹의 미래 모습이 어떨 것이라 생각하는가? 'Program > SilverLite | WPF' 카테고리의 다른 글
SilverLite Info CenterProgram/SilverLite | WPF 2008. 1. 16. 09:48실버 라이트를 개발와 디자인 측면에서 학습 할 수 있는 사이트
다운 로드 : http://msdn2.microsoft.com/ko-kr/silverlight/bb187452.aspx 소개 설명 : http://msdn2.microsoft.com/ko-kr/silverlight/bb187401.aspx 'Program > SilverLite | WPF' 카테고리의 다른 글
|